

ETL / ELT pipelines are a hot topic in the data world right now, but what exactly is an ETL / ELT pipeline and what role does it play in the overall collection and analysis of data?
An ETL pipeline is a series of processes that:
-
Extracts data from a system
-
Transforms the extracted data into a usable form
-
Loads the data into a data warehouse
An ELT pipeline is very similar, but switches the transform and loading steps:
-
Extracts data from a system
-
Loads the data into a data warehouse
-
Transforms data in the warehouse into a usable form
Both pipelines have the same goal of creating clean data for analysis and decision-making, but each have their own advantages, which we will discuss later. First, let’s examine each of the steps to better understand what is happening throughout the pipeline.
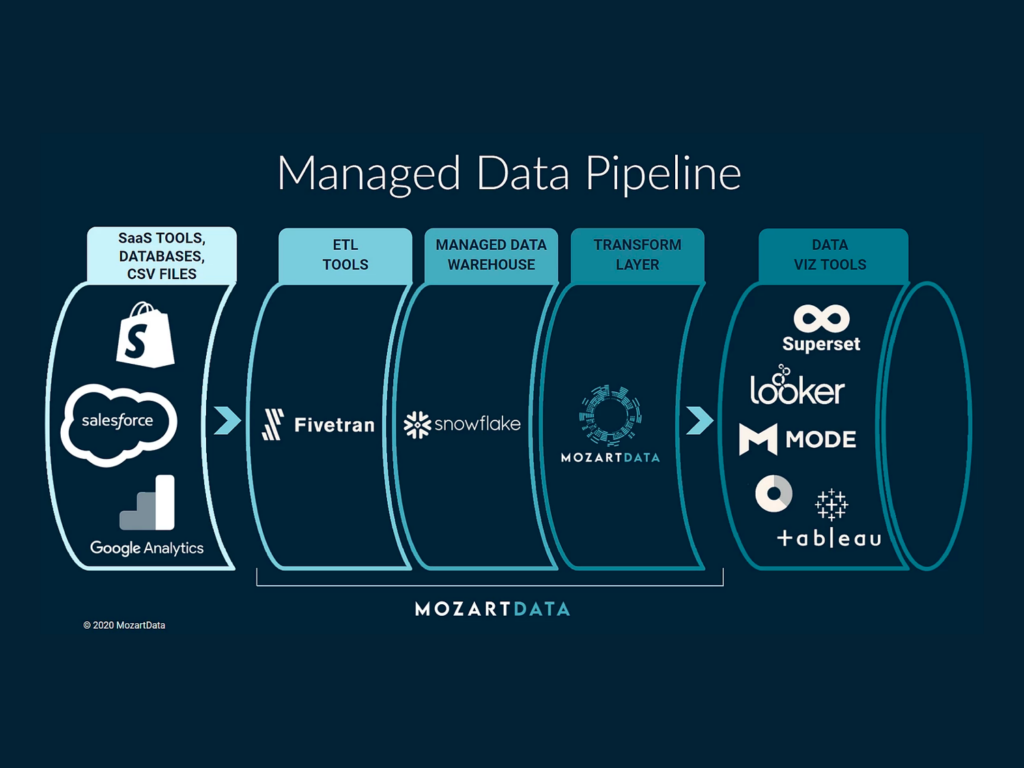
EXTRACTION
During the extraction phase, raw data is pulled from various sources, which can include (but not limited to):
-
Analytics tools (Google Analytics)
-
APIs
-
Business/HR Management Platforms (Quickbooks, Zero)
-
CRM (Salesforce, Zendesk, Freshdesk, Intercom, Kustomer)
-
Digital Marketing (Google Ads)
-
E-Commerce Platforms (Shopify, Square, Stripe)
-
Email Marketing Platforms (Klaviyo, Mailchimp, Sendgrid)
-
Product Management Tools (Airtable, Jira)
-
Product/Website Analytics (Google Analytics, Heap, Mixpanel)
-
Spreadsheets (Google Sheets)
TRANSFORMATION
During the transformation stage, the data is passed through a series of functions which cleanse, map, and change the data into usable forms. This is the most critical stage of the pipeline as it distills all of the information down the most important, actionable data.
Examples of these customized operations and functions performed on the data include:
-
Joining data from multiple sources
-
Filtration
-
Standardization
-
Validation
-
Removing unimportant data / deduplication
-
Sorting of data to improve search performance
-
Transposition
LOADING
Depending on the pipeline you choose, loading either happens before (ETL) or after (ELT) the data is transformed. During this step, data is loaded into an end target data store. Examples of those end targets are:
-
Databases
-
Data warehouses
-
Data marts
-
Data lakes
All of these end targets are synonyms for a database that holds all of your data in one place.
The stored information can now be easily accessed, analyzed, and leveraged to make business decisions and inform on-going operations.
ETL vs. ELT Pipelines
Although the end goal is the same for both ETL and ELT pipelines, they each have their own set of advantages.
ETL Advantages:
-
Only the data you care about is loaded into the warehouse. Depending on scale, there can be significant cost savings associated with transferring and storing less data.
-
Since data is being transformed before loading it into a data warehouse, ETL is more effective for confidential information (like GDPR or HIPAA). That sensitive data can be removed, masked, or encrypted before loading it into a warehouse.
ELT Advantages:
-
The main advantage of ELT is flexibility and ease of storing new data. ELT pipelines require less maintenance since they utilize automation instead of manual updates to extract new data.
-
Server infrastructure costs have decreased significantly in the last few years so copying everything is becoming increasingly affordable.
An Effective ETL / ELT Pipeline Can Enhance Business Operations
An effective data pipeline is an integral part of successful business operations. However, creating an effective one can be challenging to implement without having the right people to do it. Even with the right team, building that pipeline is time consuming and expensive. Furthermore, the underlying data sources that the data pipeline consumes are constantly changing, so there is ongoing maintenance needed to keep it updated.
Leveraging a third party to build and maintain your ETL / ELT pipeline can quickly transform how you access and use your data, and save you a lot of money on data engineering time in the process.
Mozart Data connects to your data sources, extracts your data, organizes it, and transforms it into a usable form that you can analyze and utilize as you see fit. With Mozart, you can set this up in under an hour!
—
Does your business need help building and maintaining a managed data pipeline? Request a demo of how Mozart can set one up in no time.
Interested in creating the data tools of the future? Join us! — check out our open roles on our careers page.


